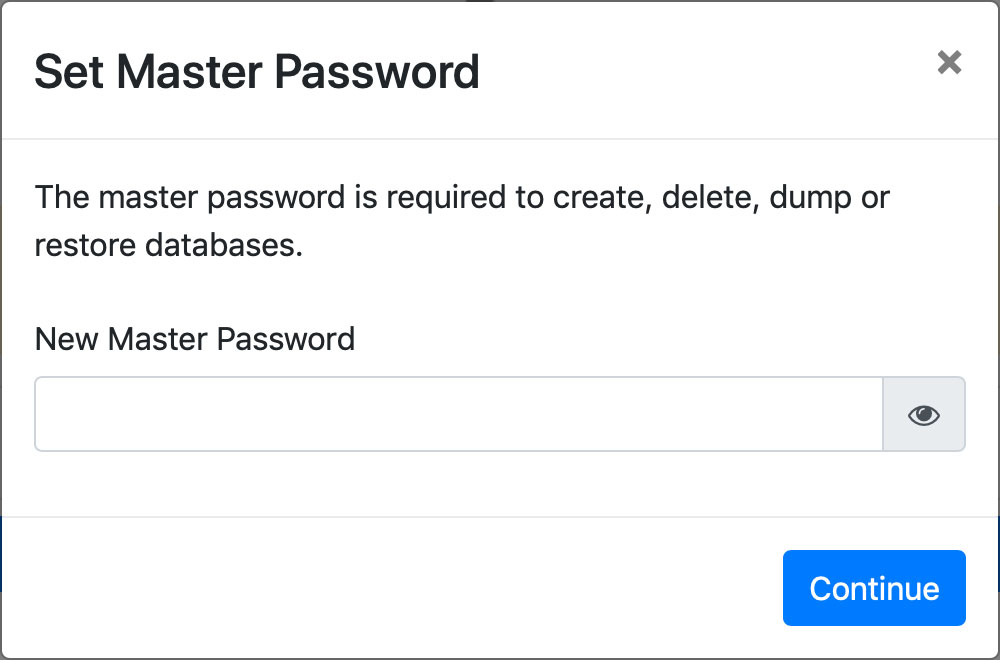
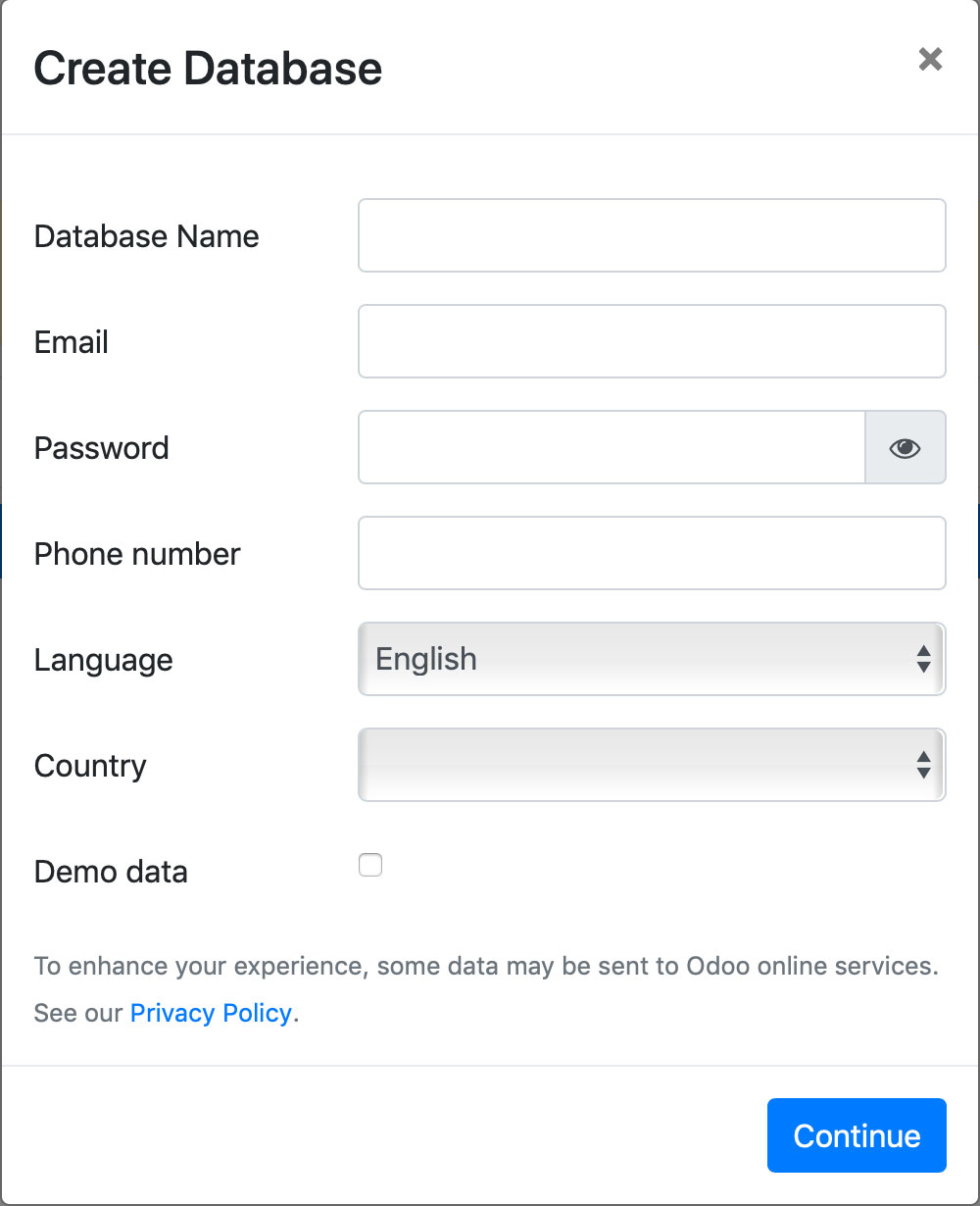
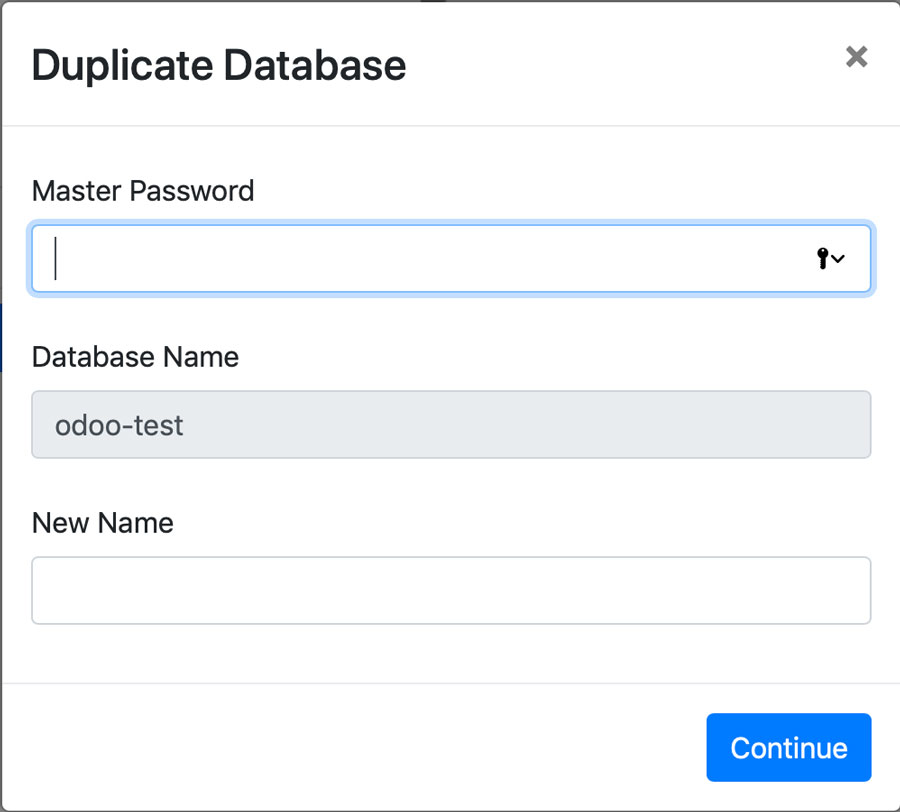
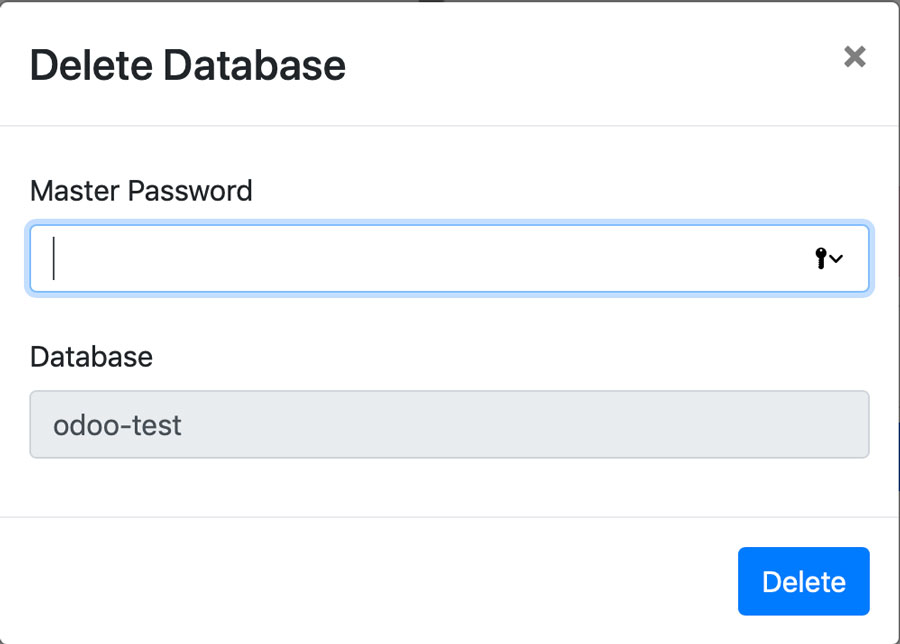
读者可能会想在堆上存储内容有什么坏处呢?有两个性能相关的问题。第一是垃圾回收器执行操作会耗费时间。追踪堆中所有空闲内存的可用块或哪些已用内存堆还持有有效指针消耗并不算小。这会占用程序执行本可使用的宝贵时间。编写了很多种内存回收算法,粗略分为两类:设计用于高吞吐(在单次扫描中发现尽可能多的垃圾)或低延时(尽快完成垃圾扫描)。Jeff Dean,Google工程化成功的幕后大神,作为联合作者于2013年发表了名为The Tail at Scale的论文。其中论述到系统应优化延时,保持低响应时间。Go运行所使用的垃圾回收器更倾向低延时。每次垃圾回收周期被设计为小于500毫秒。但如果你的Go程序创建了大量的垃圾,那么在一个周期中就无法发现发现的垃圾,这会拖慢回收器并增加内存占用。
Go开发还有一个重要的工具,但无需安装。访问The Go Playground 就可以看到类似图1-3中的界面。如果使用过irb、node或python这些命令行环境,会发现The Go Playground的使用体验非常类似。它可用于测试和分享简单程序。在窗口中输入代码,点击Run按钮运行代码。Format按钮对程序运行go fmt同时更新导入包。Share按钮创建一个唯一URL,可发送给其他人查看该程序或是你自己在未来回来查看代码(这些URL验证下来可保存很长时间,但不要把它用成代码仓库)。
注意The Go Playground实际上是别人的电脑(具体来说是Google的电脑),所有自由度受限。它提供了几种Go版本(通常是当前发行版、上一版和最新的开发版)。只能发起对localhost的网络连接,运行太长或占用过多内存时会停止掉进程。如果程序中用到时间的话,需要考虑到时钟设置为November 10, 2009, 23:00:00 UTC(Go首次发布的日期)。虽然有这些限制,Go Playground对于测试新想法很有用,而且不需要在本地新建项目。在本系列文章中,读者会看到很多The Go Playground的链接,可直接运行代码,无需拷贝到本地。
Odoo有两个版本。第一个是社区版,完全开源,另一个是企业版,需要支付授权证书费用。不同于其它软件供应商,Odoo企业版仅仅是在社区版基础上添加了一些附加特性或新应用的高级应用。基本上,企业版运行于社区版之上。社区版采用Lesser General Public License v3.0 (LGPLv3)许可证书,并带有企业版企业资源计划(ERP)的所有基础应用,如销售、客户关系管理(CRM)、发票、采购、网站构建器等等。而企业版采用 Odoo 企业版许可证书,这是一个自有证书。Odoo 企业版带有很多高级功能如完整的财务、studio、基于IP的语音传输(VoIP)、移动端响应式设计、电子签名、营销自动化、快递与银行的集成以及IoT等。企业版还为你提供无限的漏洞修复支持。下图显示了企业版依赖于社区版,这也是为什么使用企业版时需要用到社区版:
📝Odoo有数量庞大的社区开发人员,这也是你在应用商店中看到有大量的第三方应用(模块)的原因。有些免费应用使用Affero General Public License version 3 (AGPLv3)许可证书。如果你的应用依赖于这些应用就不能使用其自有证书。Odoo自有证书的应用仅能在拥有LGPL或其它自有证书的模块基础上进行开发。
出于安全考虑,应确保proxy_mode参数设为True。这是因为在Nginx作为代理时,所有的请求都会认为是来自本地而不是远程 IP 地址。在代理中设置X-ForwardedFor头以及启动–proxy-mode可解决这一问题。但是,如果不在代理级别强制header就启用–proxy-mode 会让其他人可以伪装远程地址。
但这不是真正的看板,看板应是一个组织成不同列的卡片,当然看板视图也支持这种布局。可能过 CRM 或项目应用来查看示例。访问CRM > Sales > My Pipeline可得到如下结果:
这两种布局的最大区别是卡片按列的组织方式。这通过 Group By 功能实现,与列表视图中相似。通常分组是通过stage字段实现。看板视图的一个非常有用的功能是可以在列之间拖放卡片,自动分配分组视图字段的对应值。从两个示例中的卡片我们可以看到一些分别。其实它们的设计非常灵活,设计看板卡片不只有一种方式。这两个示例为我们提供设计的一些基础。
我们将改进一直以来开发的library_checkout模型,为图书借阅添加看板视图。为此我们使用一个新文件library_checkout/views/checkout_kanban_view.xml。需要在__manifest__.py文件的 data 键最下方添加这个文件。在library_checkout/views/library_menu.xml文件中,可以看到借阅菜单项使用的窗口操作。需要对其修改来启用本文中添加的视图类型:
然后我们的<templates>元素包含一个或多个QWeb模板来生成要使用的 HTML 片断。必须要有一个名为kanban-box的模板,它渲染看板卡片。还可以添加其它模板,通常用于定义主模板中复用到的 HTML 片断。这些模板使用标准的 HTML 和 QWeb 模板语言。QWeb提供了一些特殊指令,用于处理动态生成最终展示的 HTML。
ℹ️Odoo 12中的修改 Odoo 现在使用 Twitter Bootstrap 4,此前版本中使用Bootstrap 3。这些样式在渲染 HTML 的地方通常都可使用,有关Bootstrap更多知识请见官方网站。
<t t-name="kanban-box"> <!-- Set the Kanban Card color --> <div t-attf-class=" oe_kanban_color_#{kanban_getcolor(record.color.raw_value)} oe_kanban_global_click"> <div class="o_dropdown_kanban dropdown"> <!-- Top-right drop down menu here... --> </div> <div class="oe_kanban_body"> <!-- Content elements and fields go here... --> </div> <div class="oe_kanban_footer"> <div class="oe_kanban_footer_left"> <!-- Left hand footer... --> </div> <div class="oe_kanban_footer_right"> <!-- Right hand footer... --> </div> </div> <div class="oe_clear" /> </div> </t>
可以看到如何根据记录字段值来显示或隐藏选项,Set as Done仅在未设置is_done 字段时才会显示。最后一个选项添加颜色拾取器组件来使用 color 数据字段选择或修改卡片背景色。因此,除<button>元素外,<a>也可用于运行Odoo 操作。
看板视图中的操作
在QWeb模板中,用于超链的<a>标签可带有一个 type 属性。它设置链接执行的操作类型,这样链接和常规表单中的按钮可进行同样的操作。和表单视图一样,操作类型可以是action或object,并应带有一个 name 属性来标识所要执行的具体操作。此外,还有以下操作类型可以使用:
open打开相应的表单视图
edit在编辑模式下直接打开相应的表单视图
delete删除记录并从看板视图中删除该项
QWeb 模板语言
QWeb会查找模板中的特殊指令并替换为动态生成的 HTML。这些指令是 XML 元素属性,可以用在<div>, <span>或<field>等有效标签或元素中。有时我们要使用QWeb指令但不希望放在模板的 XML 元素中。对这种情况,可以使用能带有 QWeb 指令(如t-if或t-foreach)的特殊元素<t>,该元组不会在最终产生的XML/HTML有任何输出。
QWeb模板可作为可复用的 HTML 片段插入到其它模板中。我们无需重复相同的 HTML 代码块,可以设计构成部分来组成更为复杂的用户界面视图,可复用的模板在<templates>标签中定义,通过顶级元素中 kanban-box 以外的 t-name值进行标识。这些模板可通过t-call来进行包含,在当前看板视图、相同模块的其它地方以及其它插件模块中均可。
follower头像列表可以通过可复用代码段来进行分离,下面通过子模板重写代码。首先应在 XML 文件中添加另一个模板,在<templates>元素内,<t t-name="kanban-box">节点之后,添加如下代码:
但这不是真正的看板,看板应是一个组织成不同列的卡片,当然看板视图也支持这种布局。可能过 CRM 或项目应用来查看示例。访问CRM > Sales > My Pipeline可得到如下结果:
这两种布局的最大区别是卡片按列的组织方式。这通过 Group By 功能实现,与列表视图中相似。通常分组是通过stage字段实现。看板视图的一个非常有用的功能是可以在列之间拖放卡片,自动分配分组视图字段的对应值。从两个示例中的卡片我们可以看到一些分别。其实它们的设计非常灵活,设计看板卡片不只有一种方式。这两个示例为我们提供设计的一些基础。
我们将改进一直以来开发的library_checkout模型,为图书借阅添加看板视图。为此我们使用一个新文件library_checkout/views/checkout_kanban_view.xml。需要在__manifest__.py文件的 data 键最下方添加这个文件。在library_checkout/views/library_menu.xml文件中,可以看到借阅菜单项使用的窗口操作。需要对其修改来启用本文中添加的视图类型:
然后我们的<templates>元素包含一个或多个QWeb模板来生成要使用的 HTML 片断。必须要有一个名为kanban-box的模板,它渲染看板卡片。还可以添加其它模板,通常用于定义主模板中复用到的 HTML 片断。这些模板使用标准的 HTML 和 QWeb 模板语言。QWeb提供了一些特殊指令,用于处理动态生成最终展示的 HTML。
ℹ️Odoo 12中的修改 Odoo 现在使用 Twitter Bootstrap 4,此前版本中使用Bootstrap 3。这些样式在渲染 HTML 的地方通常都可使用,有关Bootstrap更多知识请见官方网站。
<t t-name="kanban-box"> <!-- Set the Kanban Card color --> <div t-attf-class=" oe_kanban_color_#{kanban_getcolor(record.color.raw_value)} oe_kanban_global_click"> <div class="o_dropdown_kanban dropdown"> <!-- Top-right drop down menu here... --> </div> <div class="oe_kanban_body"> <!-- Content elements and fields go here... --> </div> <div class="oe_kanban_footer"> <div class="oe_kanban_footer_left"> <!-- Left hand footer... --> </div> <div class="oe_kanban_footer_right"> <!-- Right hand footer... --> </div> </div> <div class="oe_clear" /> </div> </t>
可以看到如何根据记录字段值来显示或隐藏选项,Set as Done仅在未设置is_done 字段时才会显示。最后一个选项添加颜色拾取器组件来使用 color 数据字段选择或修改卡片背景色。因此,除
看板视图中的操作
在QWeb模板中,用于超链的<a>标签可带有一个 type 属性。它设置链接执行的操作类型,这样链接和常规表单中的按钮可进行同样的操作。和表单视图一样,操作类型可以是action或object,并应带有一个 name 属性来标识所要执行的具体操作。此外,还有以下操作类型可以使用:
open打开相应的表单视图
edit在编辑模式下直接打开相应的表单视图
delete删除记录并从看板视图中删除该项
QWeb 模板语言
QWeb会查找模板中的特殊指令并替换为动态生成的 HTML。这些指令是 XML 元素属性,可以用在<div>, <span>或<field>等有效标签或元素中。有时我们要使用QWeb指令但不希望放在模板的 XML 元素中。对这种情况,可以使用能带有 QWeb 指令(如t-if或t-foreach)的特殊元素<t>,该元组不会在最终产生的XML/HTML有任何输出。
QWeb模板可作为可复用的 HTML 片段插入到其它模板中。我们无需重复相同的 HTML 代码块,可以设计构成部分来组成更为复杂的用户界面视图,可复用的模板在<templates>标签中定义,通过顶级元素中 kanban-box 以外的 t-name值进行标识。这些模板可通过t-call来进行包含,在当前看板视图、相同模块的其它地方以及其它插件模块中均可。
follower头像列表可以通过可复用代码段来进行分离,下面通过子模板重写代码。首先应在 XML 文件中添加另一个模板,在<templates>元素内,<t t-name="kanban-box">节点之后,添加如下代码: